Downloads
The Tongan Lexicon Project: Commonly-used 4,013 Tongan Words and 559 Nonwords
Katsuo Tamaoka (Corresponding Author)
Hunan University, China; Nagoya University, Japan
ktamaoka@gc4.so-net.ne.jp
Shaoyun Yu
The Hong Kong Polytechnic University, China
shaoyun.yu@polyu.edu.hk
Jingyi Zhang
University of Miyazaki, Japan
jingyizhang@cc.miyazaki-u.ac.jp
Koji Miwa
Nagoya University, Japan
miwa.koji.n8@f.mail.nagoya-u.ac.jp
Masatoshi Koizumi
Tohoku University, Japan
koizumi@tohoku.ac.jp
Funding
This work was funded by a Grant-in-Aid (S) -19H05589 (PI: Masatoshi Koizumi) - from the Japanese Society for the Promotion of Science (JSPS).
Abstract
Tongan is the Austronesian language unique to have the order of verb, subject, and object (VSO). The Tongan Lexicon Project (TLP) involved the collection of commonly-used 4,013 words and 559 nonwords. The TLP data consists of lexical decision times, accuracies, meaning, part of speech, and the numbers of phonemes and moras. To make it possible to use as a dictionary, the Web-accessible engine searchable from both Tongan spelling and English meaning are constructed, available at https://tonganlex.vercel.app/. The whole TLP data may also be downloaded separately for words and nonwords as an Excel file from the same Web site.
Keywords: lexicon project, Tongan, minority language, lexical decision, Web-accessible search engine
Previous lexicon projects have been built around the major languages provide a large scale of data for investigating the cognitive mechanism of lexical processing. The English Lexicon Project (Balota, et al., 2007) contains data of naming latencies and lexical decision times for 40,481 English words and the same number of nonwords. Slightly a slightly smaller scale of the British Lexicon Project also contains 14,365 mono- and disyllabic English words and the same number of nonwords (Keuleers, et al., 2012). In languages other than English, the French Lexicon Project contains data of lexical decision times for 38,840 French words and the same number of nonwords (Ferrand et al., 2010). The Dutch Lexicon Project (Keuleers, Diependaele, & Brysbaert, 2010) also contains lexical decision data of 14,000 Dutch mono- and disyllabic words and the same number of nonwords.
Unlike, these large-scale lexicon project, the present lexicon project was undertaken to a minority language of Tongan, containing a smaller number of 4,013 Tongan commonly-used words and 559 nonwords. Yet, as for a minority language, the scale of the Tongan Lexicon Project (TLP) is relatively large. Tongan is the Austronesian language unique to have the verb initial order of verb, subject, and object, VSO (Churchward, 1953; Custis, 2004; Dixon, 1979, 1994; Otsuka, 2000, 2005a, 2005b). This lexicon project would have a unique contribution for constructing psycholinguistic studies of a minority language for lexical, phrasal, and sentential processing.
English Proficiency among Native Tongan Speakers
Many speakers of minority languages use other major languages such as English, Spanish, French in daily life. These dominant languages are typically used at school for learning. As a result, one of these languages becomes the primary language, rather than the minority language. In such a situation, the minority language may function like a second language: the cognitive processing of the minority language may be strongly influenced by the dominant language.
The Kingdom of Tonga is a Polynesian country located in the South Pacific Ocean which has 171 islands with a population of 104,494 in 2021. Approximately 79% of the population reside on the main island of Tongatapu. Tonga was a former British protectorate from 1900 until 1970 after which time it became an independent nation within the British Commonwealth. Although Tongan children basically grow up with Tongan as their mother tongue, most Tongan speakers have enjoyed a comparatively high-level of education in English and are therefore relatively fluent in English. Because of globalization, the socioeconomically beneficial language of English is frequently used in Tonga (Otsuka, 2007). Therefore, prior to initiate the Tongan Lexicon Project, both subjective language use and proficiency was investigated to ascertain whether Tongan is the primary language for native people in Tonga.
Regarding their use of the two languages and their perceptions of their own language proficiencies, a questionnaire survey was conducted on 48 native Tongan speakers (33 female and 15 male, average age of 22 years and 9 months with the standard deviation of 4 years and 7 months ranging from 17 years and 3 months to 35 years and 0 months) to ascertain use percentage and subjective proficiency of Tongan and English. These 48 participants are not participated in the Tongan Lexicon Project.
The survey found that the mean use percentage of Tongan in daily life was 79.98% (SD=15.35%) whereas the mean use for English was 23.92% (SD=15.26%). This 64.63% usage difference between Tongan and English was significant [F(1, 47)=138.91, p<.001, ηp2=0.75]. supjective proficiency judgements of the four skills of speaking, listening, reading and writing for Tongan and English were measured using a 0-to-6 point scale (0 'none' to 6 'very high'): Speaking skills between Tongan (M=5.60, SD=0.64) and English (M=4.38, SD=0.91) differed significantly [F(1, 47)=62.57, p<.001, ηp2=0.57]; listening skills between Tongan (M=5.50, SD=0.74) and English (M=4.58, SD=1.09) differed significantly [F(1, 47)=38.17, p<.001, ηp2=0.45]; reading skills between Tongan (M=5.56, SD=0.60) and English (M=4.81, SD=0.98) differed significantly [F(1, 47)=31.67, p<.001, ηp2=0.40]; lastly, writing skills between Tongan (M=5.31, SD=0.78) and English (M=4.60, SD=1.11) also differed significantly [F(1, 47)=14.16, p<.001, ηp2=0.23].
Both subjective indexes of language use percentages and subjective language skill judgments indicated a high level of proficiency in Tongan, and lesser level of proficiency in English. Tongan is considered as their first language: the influence of English on Tongan would be weaker. Consequently, it would be possible to inspect the language processing of Tongan relatively independently from the influence of English.
Possible English Effects on Tongan Phonological Processing
Extensive exposure to a second language (L2) would affect the initially selected unit during phonological encoding (i.e., initial phonological unit, IPU). This is important as it has been argued for Chinese-English bilinguals that increased proficiency in an English may lead to sub-syllabic priming effects even in their first language of Chinese (e.g., O'Séaghdha et al. 2010; Verdonschot et al. 2013, 2015; Wang et al. 2018; You et al. 2012; Zhang & Damian 2019). Likewise, in the processing of L2 English by Japanese, Nakayama et al. (2016) found that low-proficiency Japanese-English bilinguals rely heavily on a mora unit of their first language (L1) of Japanese as IPU to process L2 English, whereas highly proficient bilinguals develop a more English native-like phonemic IPU for processing L2 English. These results suggest that extensive exposure to L2 phonology could develop a native-like IPU, which would further possibly affect IPU of L1 as well.
Since English is used frequently in daily life in Tonga, native Tongan speakers would become sensitive to phonemes even though Tongan would be basically the mora language. Tongan Laten script denotes individual phonemes which may perhaps have instilled phonemic awareness into native Tongan speakers. Consequently, phonological processing by native Tongan speakers would be susceptible to orthographic confounds. As evidence of the influence of English on Tongan phonological processing, Tamaoka et al (2022) found that both onset and mora overlapping distractors resulted in faster naming latencies for a picture naming in Tongan. Thus, Tongan phonological encoding likely natively uses the phoneme as IPU, not the mora. Thus, TLP included the numbers of both phonemes and moras contracting Tongan words as well as the number of alphabet letters.
The Tongan Lexicon Project (TLP)
A minority language of Tongan has unique linguistic features, so it would be useful to have the database for commonly-used words including part of speech and meanings as well as psycholinguistic information of lexical decision times and accuracies. For this purpose, the project developed a fee accessible Web-accessible search engine which can look up multiple words from both Tongan spelling and English meaning. The database provides ten different information (columns) for each word. The reaction times and accuracies of Tongan words were collected in the following procedure.
Method for lexical decisions
Participants
Removing two participants who showed lower than 70% of total accuracy, 168 participants (109 females and 56 males, and only two left-handed) took part in the project. Their ages ranged from 16 years and 11 months to 33 years and 4 months. The average age was 25 years and 11 months with the standard deviation of 4 years and 8 months. All participants received monetary compensation in exchange for their participation and provided written informed consent.
Words and Nonwords
A total of commonly-used 4,256 Tongan words selected from a dictionary of the Student's English-Tongan and Tongan-English Dictionary (Thompson & Thompson, 1992). Among them, 243 words with less than 70% correct responses were removed, leaving 4,013 words (94.29%) as the vocabulary for TLP. A total of 608 nonwords were created. Likewise, 49 nonwords with less than 70% of correct response were removed, resulting 559 nonwords (91.94%). All 168 participants performed all nonwords.
Procedure and Apparatus
The experiment for Tongan lexical decisions was conducted in the following procedure. First, the eye fixation of '+' was initially presented at the center of the computer screen for 500 ms, and then replaced by a target word. Participants were required to decide whether the presented word exists in Tongan by pressing the YES key for exist or the NO key for not exist. After pressing either key, the next trial started after 200 ms. The participants were asked to perform the lexical decision task as quickly and accurately as possible. All stimulus words were randomly presented for each participant. Each participant performed 16 blocks of Tongan lexical decisions, each of which consisted of 38 words and the same number of nonwords (a total of 76 items) except the last 16th block to control the total number of items. After each block is completed, a participant is recommended to rest for 30 seconds. Before the real experiment started, twelve practice items were given. The experiment was conducted individually face-to-face in a quiet room by a native Tongan experimenter using her own computer connected to the internet experimental program Pavlovia ([https://pavlovia.org/]{.underline}).
Results of Lexical Decisions
The 169 participants (removed two) had the average accuracy of 95.40% with the standard deviation of 6.33% for the final list of 4,013 Tongan words. Reaction times of lexical decisions for these 4,013 words ranged from 421 milliseconds (ms) to 949 ms. The average reaction times was 575 ms with the standard deviation of 68 ms. As for 559 nonwords, the average accuracy was 92.62% with the standard deviation of 6.49%. Reaction times were ranged from 527 ms to 801 ms. The average of reaction times for nonwords was 616.89 ms with the standard deviation of 46.58 ms. The Excel files for the 4,013 words and the 559 nonwords can be found at the Web site of the at https://tonganlex-9wpdugkq8-syu.vercel.app/. The detailed information regarding the data of the Tongan Lexicon Project is explained in the following sections.
Web-accessible Search for commonly-used 4013 Tongan words
The Web-accessible search engine has the two-way search. A Tongan word can be found by inputting alphabet spelling. For example, when imputing afi meaning 'fire' in the input window of Tongan word, all words including the inputted spelling are searched and displayed. As a result, eight words such as efiafi 'afternoon', fafine 'women' and fakafiefia 'joy' will be shown in a screen. It is also possible to search from an English meaning. When imputing fire, six related words including afi and fale tāmate-afi 'firestation', fefie 'firewood, fuel', feitunu 'to cook food over an open fire' will be displayed. The search function from Tongan and from an English meaning would be useful to find intended Tongan words for constructing a stimulus phrase and sentence. All displayed lexical items included the following information in 10 columns.
Column 1: Tongan Words (Spelling)
The first column displays a Tongan word in alphabets. For example, a Tongan word, moʻunga meaning 'a mountain'.
Column 2: Dictionary Page
The words are originally taken from the dictionary of The Student's English-Tongan and Tongan-English Dictionary written by Richard H. Thompson and 'Ofa Thompson in 1992 at https://friendlyisles.press/books/. A page number of a word in the dictionary is specified in the second column. For example, afi 'fire' is listed in Page 71. In the dictionary, English words are listed in the first half while Tongan words are listed in the second half in the alphabetic order, so afi is listed in a relatively later page.
Column 3: Number of Letters
The number of letters ranged from 1 to 23. The mean is 7.59 with the standard deviation of 2.96. Words in Tongan are described in the Laten script, so each letter basically represents a phonemic unit. However, three cases of (1) long vowel, (2) voiced velar nasal spelled ng, and (3) a glottal plosive are required attention. First, a long vowel (macron) is written in a single letter with the bar like ā and ō, but it is counted as two phonemes. A noun kāloti 'carrot' is an English loanword. This word is written in six letters but counted as seven phonemes because kā is counted as three phonemes (/k/ + /a/ + /a/). Second, the spelling of ng is counted as two letters. However, consonant combinations are not allowed in Tongan, so ng cannot be split two consonants. It represents a single consonant of voiced velar nasal [ŋ]. A word engeenga 'yellow' is written in eight letters but counted as six phonemes /e/, /ng/, /e/, /e/, /ng/ and /a/, and four syllables /e/, /nge/, /e/ and /nga/. Third, a glottal plosive (fakauʻa in Tonga) is described by an upper conman ʻ which puts before a vowel. This is considered as a single consonant, so it is counted as a single letter. For instance, a word foʻi ʻakau 'fruit' is counted as 9 letters and 9 phonemes. In addition to these three features, hyphens do not count as a single letter. For example, anga-faingata'a meaning 'not easy-going' or 'difficult to approach or relate with' has a hyphen, but this is not counted as a single letter in the present project.
Column 4: Number of Phonemes
The Tongan language has a limited number of phonemes consisting of twelve consonants (p, m, f, v, t, s, n, k, l, ŋ, ʔ, and h) and five vowels (i, e, a, u, o; cf. Garellek & White, 2015). The phonetic ʔ is a glottal plosive (fakauʻa in Tongan) written in the upper comma '. The number of phonemes ranged from 1 to 24. The mean is 7.63 with the standard deviation of 2.92. As mentioned in the section of Number of Letters, three cases of (1) long vowel, (2) voiced velar nasal ng, and (3) a glottal plosive ' are required attention regarding the number of phonemes as well.
Column 5: Number of Moras
The basic rhythmic unit in Tongan to be a combination of moras with a strong first and a weak second mora (Hayes, 1995). Tongan has a rigid syllabic structure having only (C)V syllables (Anderson & Otsuka, 2006). Mono-moraic words in Tongan typically serve a grammatical function such as ki meaning 'to/towards', and pe meaning 'or'. Words carrying meaning like kolo meaning 'town' usually have more than one mora. A simple rule to determine the number of moras in a Tongan word is to count the vowels. For example, feke meaning 'octopus' has two vowels: therefore, two moras as /fe/ and /ke/. It should be noted that a long wovel mā (/ma/+/a/) with two vowels of /a/ is counted as two moras. The number of moras ranged from 1 to 13. The mean is 4.17 with the standard deviation of 1.58.
Column 6: Part of Speech
The parts of speech were classified into 16 different categories: adjective, adverb, article, conjunction, (idiomatic) expression, interjection, interrogative, noun, numeral, plural marker, prefix, preposition, pronoun, quantifier, tense marker, and verb. Many words are used for multiple parts of speech, so these are described such as adjective/verb, adjective/noun, conjunction/adverb, interrogative/adverb, noun/verb etc.
Column 7: Meaning in English
Meanings of commonly-used 4,256 Tongan words are basically taken from the dictionary of the Student's English-Tongan and Tongan-English Dictionary (Thompson & Thompson, 1992). For example, foʻou is describe as '(adj/v) new, fresh; strange, unfamiliar'. The meaning starts with its part(s) of speech (adj=adjective, v=verb), and the meaning in English follows.
Column 8: Number of Participants
The number of participants indicate the total participants who responded a target word. For example, 24 native Tongan speakers correctly responded the word fale ta'o-mā 'bakery', so it is written in '24'. The number of participants range from 22 to 32. Responses to all Tongan words were controlled to have more than 22 participants. The mean is 26.04 participants with the standard deviation of 2.94.
Column 9: Reaction Times
Reaction times for Tongan lexical dedications are recorded for each word. As shown in Figure 1 of a density plot, the distribution of reaction times is positively skewed (skewness = 0.97), indicating that reaction times showed a left-skewed distribution. Sine the skewness value is still between -1 and 1, it is acceptable range. The distribution also showed the slightly steeper peak (kurtosis = 1.38). The value of kurtosis is also acceptable range. Normality tests of both Shapiro Wilk (N=4,013, W = 0.95, p<.001) and Kolmogorov-Smirnov (*N=*4,013, K= 0.95, p<.001) was highly significant, so the distribution of reaction times is not normally distributed.
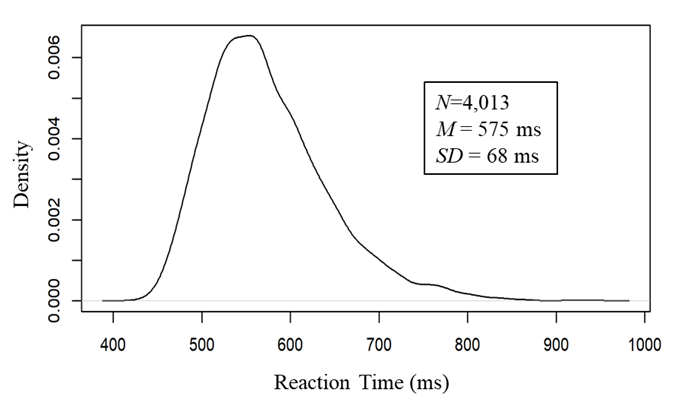
Figure 1. Density plot for reaction times
To attenuate skewness in the distribution, reaction times were transformed to both natural logarithm (loge) and reciprocals (-1000/rt, rt = reaction time). The quantile-quantile (QQ) plots were drowned in Figure 2. In a QQ plot, the linearity of the points suggests a normal distribution (Wilk & Gnanadesikan, 1968). The row reaction time data shows to be away from the identity line between sample quantiles and theoretical quantiles. Data transformed to natural logarithm still shows to be slightly away from the identity line. From Figure 2, reciprocal transformation seems to show a better linearity, so it would be better to apply for reaction times when analyze the data.
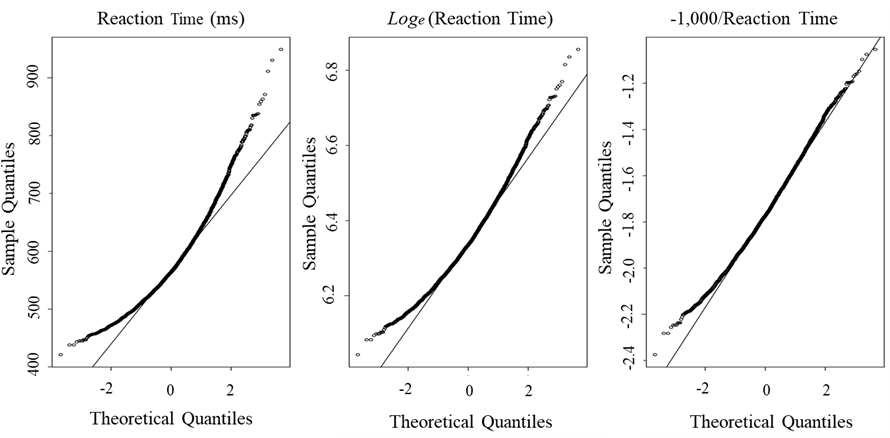
Figure 2. Quantile-quantile (QQ) plot of reaction times,
natural logarithm (Loge) and reciprocals
Column 10: Accuracy
Unlike reaction times, accuracy data is heavily skewed since many Tongan words were correctly identified accurately at 100% (1.00). As shown in Figure 3, distribution of accuracy data is negatively skewed (skewness =-1.83) and have the steeper peak (kurtosis = 3.09).
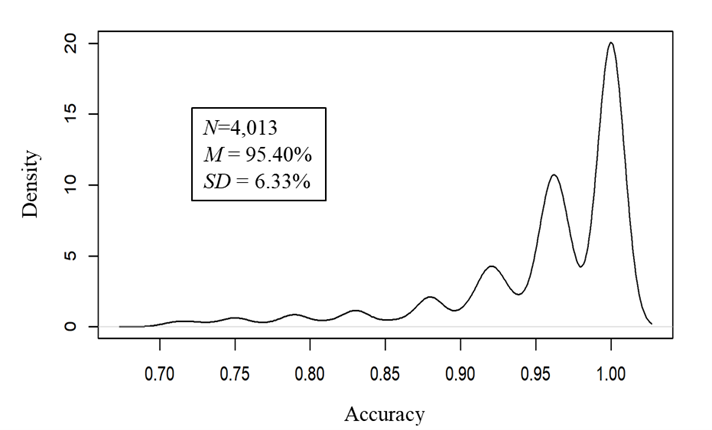
Figure 3. Density plot for accuracies
599 Nonwords Used for Tongan Lexical Decisions
The data for 599 Nonwords performed by all 168 participants was given in an Excel file which may download from https://tonganlex.vercel.app/. Data consisted of four columns, (1) nonword spelling, (2) number of letters, (3) reaction times and (4) accuracies. There is no Web-accessible search engine for nonwords.
Further analysis and discussion
(Placeholder)
References
Anderson, V., & Otsuka, Y. (2006). The phonetics and phonology of "definitive accent" in Tongan. Oceanic Linguistics, 45(1), 21--42.
Balota, D. A., Yap, M. J., Cortese, M. J., Hutchison, K. A., Kessler, B., Loftis, B., Neely, J. H., Nelson, D. L., Simpson G. B. & Treiman, R. (2007). The English Lexicon Project. Behavior Research Methods, 39, 445--459.
Churchward, C. Maxwell (1953). Tongan grammar. Oxford: Oxford University.
Custis, Tonya (2004). Word Order Variation in Tongan: A Syntactic Analysis. Doctoral dissertation at the University of Minnesota.
Dixon, Robert M. W (1979). Ergativity. Language, 55, 59-138.
Dixon, Robert M. W (1994). Ergativity. Cambridge: Cambridge University.
Ferrand, L., New, B., Brysbaert, M., Keuleers, E., Bonin, P., Méot, A., Augustinova, M. & Pallier, C. (2010). The French Lexicon Project: Lexical decision data for 38,840 French words and 38,840 pseudowords. Behavior Research Methods, 42, 488--496.
Garellek, M., & White, J. (2015). Phonetics of Tongan stress. Journal of the international Phonetic Association, 45(1), 13--34.
Hayes, B. (1995). Metrical stress theory: Principles and case studies. University of Chicago Press.
Keuleers, E., Diependaele, K., & Brysbaert, M. (2010b). Practice effects in large-scale visual word recognition studies: A lexical decision study on 14,000 Dutch mono- and disyllabic words and nonwords. Frontiers in Language Sciences. Psychology, 1, 174. doi:10.3389/fpsyg.2010.00174.
Nakayama, M., Kinoshita, S., & Verdonschot, R.G. (2016). The Emergence of a Phoneme-sized Unit of Speech Planning in Japanese-English Bilinguals. Frontiers in Psychology. 7, 175.
O'Séaghdha, P. G., Chen, J. Y., & Chen, T. M. (2010). Proximate units in word production: Phonological encoding begins with syllables in Mandarin Chinese but with segments in English. Cognition, 115(2), 282--302.
Otsuka, Y. (2000). Ergativity in Tongan. Doctoral dissertation, University of Oxford.
Otsuka, Y. (2005a). Two derivations of VSO: a comparative study of Niuean and Tongan. In Andrew Carnie, Heidi Harley and Sheila Ann Dooley (Eds.) Verb first: On the syntax of verb-initial languages (pp. 281-302), Amsterdam: John Benjamins.
Otsuka, Y. (2005b). Scrambling and information focus: VSO-VOS alternation in Tongan. In Joachim Sabel and Mamoru Saito (Eds.) The free word order phenomenon: Its syntactic sources and diversity (pp. 243-279) Berlin: Mouton de Gruyter.
Otsuka, Y. (2007). Making a case for Tongan as an endangered language. The Contemporary Pacific, 19(2), 446-473.
Tamaoka, K., Zhang, J., Koizumi, M. & Verdonschot, R. G. (2022). Phonological encoding in Tongan: an experimental investigation. Quarterly Journal of Experimental Psychology, Online First: doi.org/10.1177/17470218221138770.
Thompson R. H., & Thompson 'O (1992). The Student's English-Tongan and Tongan-English Dictionary. Tonga: Faletohi 'Otumotu Angl'ofa'.
Verdonschot, R. G., Lai, J., Feng, C., Tamaoka, K., & Schiller, N. O. (2015). Constructing initial phonology in Mandarin Chinese: Syllabic or sub-syllabic? A masked priming investigation. Japanese Psychological Research, 57, 61--68.
Verdonschot, R. G., Nakayama, M., Zhang, Q.-F., Tamaoka, K., & Schiller, N. O. (2013). The proximate phonological unit of Chinese-English bilinguals: Proficiency matters. PLOS ONE, 8, Article e61454.
Verdonschot, R. G., Phương, H. T. L. & Tamaoka, K. (2022). Phonological encoding in Vietnamese: An experimental investigation. Quarterly Journal of Experimental Psychology, 75(7), 1355-1366.
Wang, J., Wong, A. W. K., & Chen, H. C. (2018). Time course of syllabic and sub-syllabic processing in Mandarin word production: Evidence from the picture-word interferenceparadigm. Psychonomic Bulletin & Review, 25(3), 1147-1152.
Wilk, M. B., & Gnanadesikan, R. (1968). Probability plotting methods for the analysis of data, Biometrika, 55(1), 1-17.
You, W.-P., Zhang, Q.-F., & Verdonschot, R. G. (2012). Masked syllable priming effects in word and picture naming in Chinese. PLOS ONE, 7(10), Article e46595.
Zhang, Q., & Damian, M. F. (2019). Syllables constitute proximate units for Mandarin speakers: Electrophysiological evidence from a masked priming task. Psychophysiology, 56(4), Article e13317.